

You may also like
No items found.




Most ingredient databases fail before they're finished. Not because the data is wrong — because the system was built for one person's workflow and everyone else quietly stopped using it after week two.
If you're in food R&D, you've seen this play out. A food scientist builds a beautiful spreadsheet. It lives on a shared drive. Someone updates it without telling anyone. A formulation gets approved with a supplier that's been on allocation for three months. The spreadsheet keeps existing. The problems keep compounding.
Let me walk you through what actually makes an ingredient database work for a whole R&D team — not just the person who built it.
The core problem isn't data volume. It's data structure combined with zero accountability for keeping it current.
A spreadsheet can hold thousands of ingredient records. What it can't do is alert you when a supplier changes their spec sheet, flag a cost increase from your primary vanilla source, or tell you that the stabilizer you're reformulating around just hit a 14-week lead time. Static tools create static knowledge. And in CPG, static knowledge ages fast.
The second failure mode is siloing. Procurement knows things R&D doesn't. R&D knows things regulatory doesn't. When your ingredient data lives in separate systems — or separate tabs — you're not running one database. You're running three partial ones and hoping someone bridges the gaps at exactly the right moment.
The goal of a well-built ingredient database isn't just storage. It's shared, living intelligence.
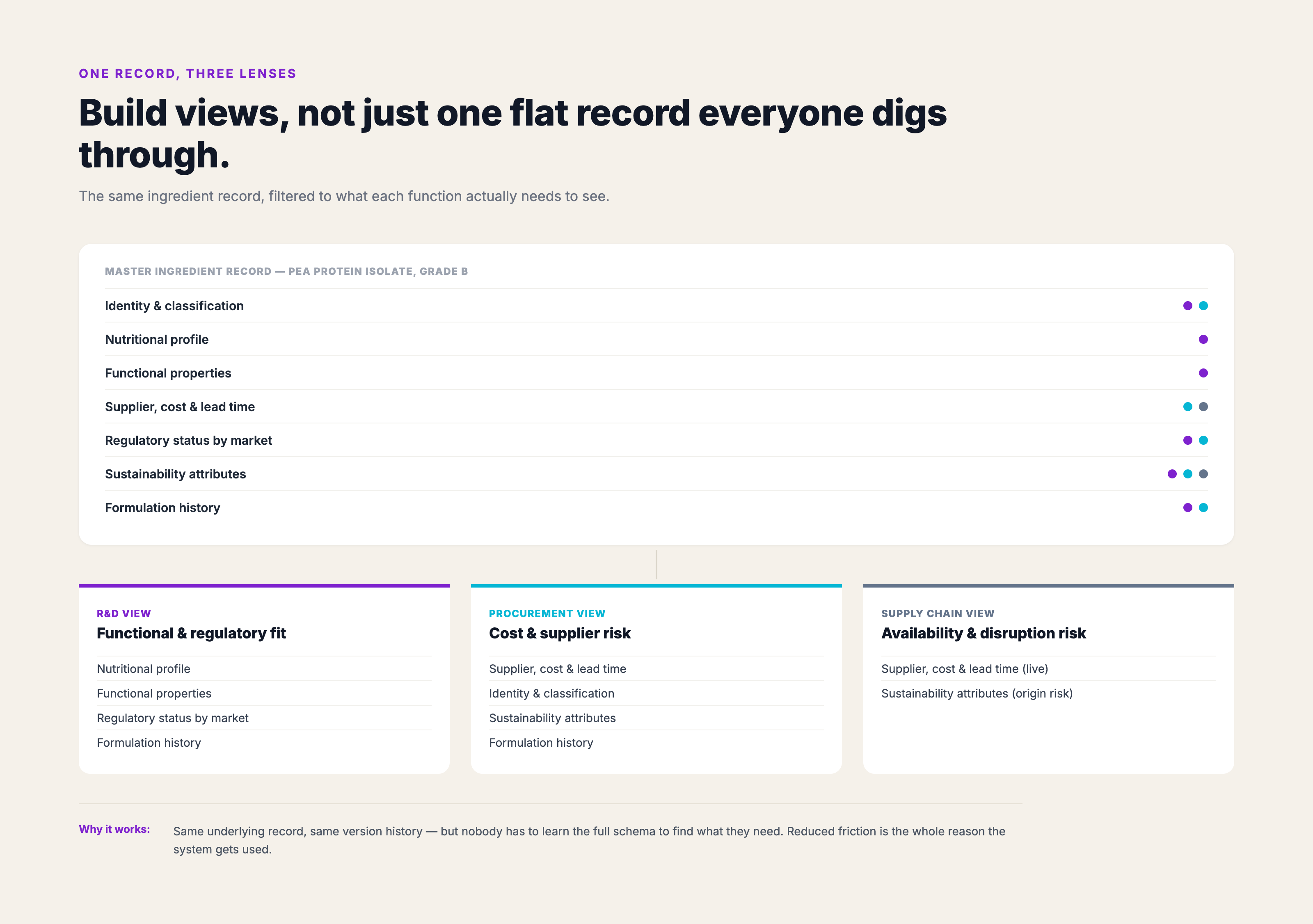
Before you think about tooling, get clear on the data model. A useful ingredient record for food R&D contains far more than a name and a supplier contact. Here's what a complete record looks like:
That last field is the one most teams skip. It's also the one that saves you when a supplier discontinues a raw material and you need to know every affected product within 10 minutes.
Here's where most builds go wrong: they optimize for the person doing data entry, not the person doing the lookup.
Your procurement lead needs supplier risk and cost trends. Your food scientist needs functional properties and regulatory constraints. Your supply chain manager needs lead times and allocation status. If everyone has to dig through the same flat record to find what they need, they'll stop using it.
Build views, not just records. A good ingredient database surfaces different data slices to different roles without requiring everyone to understand the full schema.
In practice, that means:
Role-based views reduce friction. Reduced friction means people actually use the system. That's the whole game.
If your ingredient database doesn't track changes over time, it's not a database — it's a snapshot.
Version control in ingredient management means you can answer questions like:
Without version history, you're flying blind on compliance questions, reformulation decisions, and supplier disputes. With it, you have a defensible audit trail that covers you in regulatory reviews and internal post-mortems.
This is one of the core reasons teams move away from spreadsheets toward purpose-built platforms. The version control problem is genuinely hard to solve in a shared doc environment — not impossible, but painful enough that most teams don't bother until something breaks.
Building the database is the easy part. Keeping it accurate six months later is where teams fall apart.
A few principles that actually work:
Assign ownership, not just access. Every ingredient record should have a named owner responsible for verifying it on a defined cadence. Quarterly is a reasonable starting point for most ingredients. High-risk or high-cost ingredients warrant monthly reviews.
Automate what you can. Supplier pricing updates, regulatory change alerts, and supply chain disruptions are exactly the kind of signals that should flow into your database automatically — not wait for someone to remember to check. Supply chain intelligence tools are increasingly built to do exactly this, flagging anomalies and surfacing risks before they become formulation emergencies.
Build an update trigger into your workflow. Any time a supplier changes, a formulation gets revised, or a new product launches, the ingredient records involved should be reviewed as part of that process. Make it a step, not an afterthought.
An ingredient database that sits apart from your formulation workflow is a reference tool. Useful, but limited.
The real value comes when ingredient data informs decisions in real time. When your food scientist searches for a clean-label emulsifier, they should see not just what's available — but what's been used before, what the current cost looks like, whether the primary supplier has any active alerts, and how the ingredient scores against your sustainability targets.
That kind of connected intelligence is what separates a modern ingredient database from a glorified spreadsheet. It's also what AI-powered platforms in the food industry are increasingly built to deliver — scoring ingredients across nutrition, cost, and sustainability simultaneously so your team can make faster, better-informed formulation calls.
If you're starting from scratch or trying to fix a broken system, here's a realistic sequence:
Spreadsheets work until they don't. The inflection point usually arrives when one of these things happens:
At that point, the cost of maintaining a manual system — in time, errors, and missed signals — exceeds the cost of purpose-built tooling. AI and supply chain transparency have matured to where platforms can now handle the monitoring, alerting, and scoring work that used to require a dedicated data analyst.
Journey Foods is built specifically for this problem. The platform gives R&D teams a centralized ingredient database with AI-powered scoring across nutrition, cost, and sustainability — plus supply chain alerts that keep your data current without manual chasing. If your team is at the point where a spreadsheet is costing you more than it's saving, explore what Journey Foods can do for your formulation workflow.
Most ingredient databases track cost and nutrition reasonably well. Sustainability data is usually an afterthought — added later in a separate column that nobody trusts.
Worth fixing deliberately. Retailer and consumer pressure on sustainability claims is intensifying, and supply chain sustainability decisions increasingly determine which ingredients are viable at scale, not just which ones look good on a label.
Build sustainability attributes into your core data model from the start. Country of origin, supplier certifications, estimated carbon intensity, and water usage data belong in the same record as your nutritional profile — not in a separate tab that gets updated once a year before an audit.
The best ingredient database is the one your team trusts enough to rely on for real decisions. That means the data is current, the structure matches how different functions actually work, and the system connects to your formulation process rather than sitting beside it.
None of that requires a massive infrastructure investment. It requires deliberate design, clear ownership, and the right tooling for your team's scale.
Get those three things right, and your ingredient database stops being a maintenance burden and starts being a genuine competitive asset.
We'd love to hear from you! If you have questions about building out your ingredient database — or want to share what's worked (or hasn't) for your team — throw them in the comments below.
Find us on Instagram, LinkedIn, and X.
What should an ingredient database for food R&D include?
A complete ingredient record should cover identity data (name, CAS number, category), nutritional profile, functional properties, supplier information (including backup suppliers and lead times), regulatory status by market, sustainability attributes, and formulation history showing which products use the ingredient and at what inclusion rate.
How do you keep an ingredient database current across a team?
Assign a named owner to each ingredient record with a defined review cadence — quarterly for most ingredients, monthly for high-risk or high-cost ones. Build update triggers into your formulation workflow so records get reviewed whenever a supplier changes or a product is revised. Automated supply chain alerts can handle real-time monitoring between manual reviews.
When should a food R&D team move from spreadsheets to a dedicated ingredient database platform?
The practical inflection point is usually when your team exceeds three or four people working on formulations simultaneously, when you're managing more than 200 active ingredients, or when a supply chain disruption reveals how little real-time visibility your current system actually provides.
How do you structure an ingredient database for cross-functional use?
Build role-based views rather than one flat record everyone has to navigate. Procurement needs supplier risk and pricing data. R&D needs functional properties and regulatory constraints. Sustainability teams need origin and certification data. Separate views for each function reduce friction and increase adoption.
Why is version control important in an ingredient database?
Version control lets you answer compliance and audit questions accurately — what was the spec when a product launched, who changed a supplier record and when, how a formulation evolved across versions. Without it, you have a snapshot. With it, you have a defensible audit trail.
How does AI improve ingredient database management for CPG teams?
AI-powered platforms can score ingredients across multiple dimensions simultaneously (nutrition, cost, sustainability), surface supply chain alerts automatically, and generate ingredient recommendations for reformulation — reducing the manual research burden on R&D teams and keeping data current without constant human intervention.
What's the most common reason ingredient databases fail in food companies?
Building for data entry rather than data use. If the system doesn't surface the right information to the right person at the right moment — and if there's no clear ownership for keeping records current — teams stop trusting it and revert to email threads and personal spreadsheets.






